
Deep AI 开发业界首款集成人工智能训练和推理的边缘方案
摘要:DEEPAI的解决方案运行在现成的FPGA卡上,消除了对GPU的需求,与GPU相比,它的性能功耗比或性能成本比提高了10倍。因为无需关注FPGA硬件设计,对于设计人工智能应用程序的数据科学家和开发人员来说非常方便。支持标准的深度学习框架,包括Tensorflow、Pythorch和Keras。
DEEP AI的解决方案运行在现成的FPGA卡上,消除了对GPU的需求,与GPU相比,它的性能/功耗比或性能/成本比提高了10倍。因为无需关注FPGA硬件设计,对于设计人工智能应用程序的数据科学家和开发人员来说非常方便。支持标准的深度学习框架,包括Tensorflow、Pythorch和Keras。
以往训练深度学习模型和服务推理需要昂贵、耗电量大的GPU提供大量计算资源,因此深度学习是在云端或大型内部数据中心中执行的。训练新模型需要几天甚至几周的时间才能完成,而且推理查询会受到往返云端的长时间延迟的影响。
深层人工智能LogoYet是一种输入云系统的数据,用于更新训练模型和推理查询,主要是在边缘生成的,包括商店、工厂、终端、办公楼、医院、城市设施、5G手机站点、车辆、农场、家庭和手持移动设备。在云端或数据中心之间传输快速增长的数据会导致不可持续的网络带宽、高成本和低响应速度,并损害数据隐私和安全性,降低设备自主性和应用程序可靠性。
为了克服这些局限性,Deep AI为边缘端开发了一个集成的、整体的、高效的训练和推理深度学习解决方案。使用Deep AI,应用程序开发人员可以部署一个集成的训练推理解决方案,在同一设备上并行在线推理的同时,对他们的模型进行实时再训练。
Deep-AI技术的核心是能够在8位定点进行训练,同时在训练时具有高稀疏率,而不是32位浮点和非稀疏算法,这是当今GPU的标准。这两项技术突破使得人工智能平台在性能、功耗和成本上都更为出色。当被实现到一个ASIC中时,它们可以在芯片内驱动100倍的效率。
创新算法弥补了8位定点精度较低和稀疏性较高的缺点,并将训练精度降到最低。对于边缘应用程序,使用案例通常要求使用增量数据更新对预先训练的模型进行再训练,在大多数情况下,训练精度保持,而在其他情况下,训练精度可以降低到最小。
此外,在今天的大多数系统中,训练是在32位浮点上进行的,而人们越来越希望在8位定点上运行推理。在这些情况下,需要手动运行具有挑战性以及耗时和耗资源的量化过程,以将32位训练输出转换为8位推理输入。此外,这种转换通常会导致精度的损失。因为深层人工智能的训练是在8位定点上完成的,所以它可以通过设计进行推理,并直接提供给推理。在推理之前,不需要人工干预或处理来量化训练输出,从训练到推理也不会损失精度。
DEEP AI的解决方案使用FPGA,在各种加速工作负载中的应用正在迅速增长。在深度学习方面的最新进展支持使用8位定点数字格式进行推理,并在FPGA上实现低延迟推理。Deep AI的突破性技术向前迈出了一大步,它还支持在FPGA上使用8位定点数字格式进行训练,并在同一个FPGA平台上运行训练和推理。
目前,Deep AI的解决方案可用于Xilinx和领先服务器供应商的标准现成FPGA卡上的内部部署。该解决方案还将于2021年第一季度在基于Xilinx云的FPGA即服务实例上提供。
与Xilinx、Dell Technologies和One Convergence合作
Deep AI的解决方案运行在Xilinx Alveo加速卡上,这是一种经过认证的PCI-e插卡,可在各种标准服务器上使用。同一个硬件用于深度学习模型的推理和再训练,允许一个持续的迭代过程,使模型更新为连续生成的新数据。
Xilinx软件和人工智能解决方案营销副总裁Ramine Roane说:“DEEP AI在应对深度学习模型的定点训练挑战方面的表现令人印象深刻。Xilinx很高兴能与Deep AI合作,将基于我们自适应平台的培训解决方案推向市场。”
Deep AI与Dell Technologies合作验证了PowerEdge R740xd机架式服务器(预装Xilinx Alveo加速卡)和示例网络模型和数据集,特别针对了零售和制造市场。
此外,DEEP AI为客户提供一个融合DKube完整的端到端企业MLOps平台集成的深度人工智能解决方案。
“我们很高兴与深度人工智能合作,通过我们的DKube平台为我们的客户提供具有成本效益的综合训练和推理加速解决方案,”Dkube营销和销售高级总监Ajai Tyagi说。“Dkube(https://www.dkube.io)是一个基于Kubernetes的平台,基于Kubeflow和MLFlow等开放标准,它满足了AI社区对通用集成MLOps工作流的关键需求,尤其是那些希望部署在prem和/或混合模型上的人。”
- 安森美汽车&能源基础设施白皮书下载活动时间:2024年04月01日 - 2024年10月31日[立即参与]
- 2023年安森美(onsemi)在线答题活动时间:2023年09月01日 - 2023年09月30日[查看回顾]
- 2023年安森美(onsemi)在线答题活动时间:2023年08月01日 - 2023年08月31日[查看回顾]
- 【在线答题活动】PI 智能家居热门产品,带您领略科技智慧家庭时间:2023年06月15日 - 2023年07月15日[查看回顾]
- 2023年安森美(onsemi)在线答题活动时间:2023年06月01日 - 2023年06月30日[查看回顾]
- 汽车电子电源行业可靠性要求,你了解多少?
- 内置可编程模拟功能的新型 Renesas Synergy™ 低功耗 S1JA 微控制器
- Vishay 推出高集成度且符合 IrDA® 标准的红外收发器模块
- ROHM 发布全新车载升降压电源芯片组
- 艾迈斯半导体推出行业超薄的接近/颜色传感器模块,助力实现无边框智能手机设计
- 艾迈斯半导体与 Qualcomm Technologies 集中工程优势开发适用于手机 3D 应用的主动式立体视觉解决方案
- 维谛技术(Vertiv)同时亮相南北两大高端峰会,精彩亮点不容错过
- 缤特力推出全新商务系列耳机 助力解决开放式办公的噪音难题
- CISSOID 和泰科天润(GPT)达成战略合作协议,携手推动碳化硅功率器件的广泛应用
- 瑞萨电子推出 R-Car E3 SoC,为汽车大显示屏仪表盘带来高端3D 图形处理性能
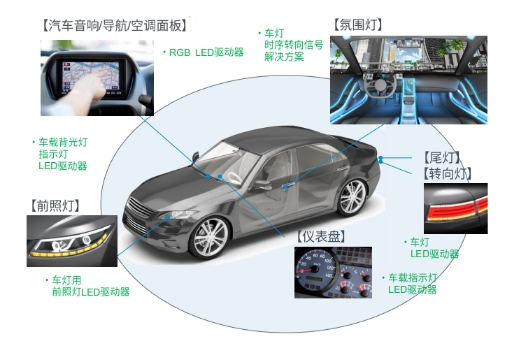
众所周知,LED的驱动IC担负着在输入电压不稳定的情况下,为LED提供恒定的电流,并控制恒定(可调)亮度的作用。无论是室内照明,还是车载应用,都肩负着极为重要的使命。
- 关于反激电源效率的一个疑问
时间:2022-07-12 浏览量:10200
- 面对热拔插阐述的瞬间大电流怎么解决
时间:2022-07-11 浏览量:8955
- PFC电路对N线进行电压采样的目的是什么
时间:2022-07-08 浏览量:9597
- RCD中的C对反激稳定性有何影响
时间:2022-07-07 浏览量:7207
- 36W单反激 传导7~10M 热机5分钟后超标 不知道哪里出了问题
时间:2022-07-07 浏览量:5981
- PFC电感计算
时间:2022-07-06 浏览量:4192
- 多相同步BUCK
时间:2010-10-03 浏览量:37872
- 大家来讨论 系列之二:开机浪涌电流究竟多大?
时间:2016-01-12 浏览量:43167
- 目前世界超NB的65W适配器
时间:2016-09-28 浏览量:60030
- 精讲双管正激电源
时间:2016-11-25 浏览量:128142
- 利用ANSYS Maxwell深入探究软磁体之----电感变压器
时间:2016-09-20 浏览量:107564
- 【文原创】认真的写了一篇基于SG3525的推挽,附有详细..
时间:2015-08-27 浏览量:100306
