
采用PIM等优化AI芯片设计的新方法
时间:2018-05-31 10:27来源:EDN电子技术设计
摘要:比利时研究机构Imec在近日举行的年度技术论坛(ITFBELGIUM2018)上透露,该机构正在打造一款采用单位元精度的深度学习推论(inference)芯片原型
比利时研究机构Imec在近日举行的年度技术论坛(ITF BELGIUM 2018)上透露,该机构正在打造一款采用单位元精度的深度学习推论(inference)芯片原型;Imec并期望在明年收集采用创新资料型态与架构──采用存储器内处理器(processor-in-memory,PIM),或是类比存储器结构(analog memory fabric)──的客户端装置有效性资料。
学术界已经研究PIM架构数十年,而该架构越来越受到资料密集的机器算法欢迎,例如新创公司Mythic以及IBM Research都有相关开发成果。许多学术研究机构正在实验1~4位元的资料型别(data type),以减轻深度学习所需的沉重存储器需求;到目前为止,包括Arm等公司的AI加速器商用芯片设计都集中在8位元或更大容量的资料型别,部分原因是编程工具例如Google的TensorFlow缺乏对较小资料型别的支援。
Imec拥有在一家晶圆代工厂制作的40奈米制程加速器逻辑部份,而现在是要在自家晶圆厂添加一个MRAM层;该机构利用SRAM模拟此设计的性能,并且评估5奈米节点的设计规则。此研究是Imec与至少两家匿名IDM业者伙伴合作、仍在开发阶段的项目,从近两年前展开,很快制作了采用某种电阻式存储器(ReRAM)的65奈米PIM设计原型。
该65奈米芯片并非锁定深度学习算法,虽然Imec展示了利用它启动一段迷人的计算机合成音乐;其学习模式是利用了根据以音乐形式呈现、从传感器所串流之资料的时间序列分析(time-series analysis)。而40奈米低功耗神经网络加速器(Low-Energy Neural Network Accelerator,LENNA)则会锁定深度学习,在相对较小型的MRAM单元中运算与储存二进制权重。
Imec技术团队的杰出成员Diederik Verkest接受EE Times采访时表示:「我们的任务是定义出我们应该利用新兴存储器为机器学习开发什么样的半导体技术──或许我们会需要制程上的调整,」以取得最佳化结果。该机构半导体技术与系统部门执行副总裁An Steegen则表示:「AI会是制程技术蓝图演化的推手,因此Imec会在AI (以及PIM架构)方面下很多功夫──这方面的工作成果将会非常重要。」
确实,如来自英国的新创公司Graphcore执行长Nigel Toon所言,AI标志着「运算技术的根本性转变」;该公司将于今年稍晚推出首款芯片。Toon在Imec年度技术论坛上发表专题演说时表示:「今日的硬件限制了我们,我们需要某种更灵活的方案…我们想看到能根据经验调整的(神经网络)模型;」他举例指出,两年前Google实习生总共花了25万美元电费,只为了在该公司采用传统x86处理器或Nvidia GPU的资料中心尝试最佳化神经网络模型。
实现复杂的折衷平衡
Imec希望LENNA能在关于PIM或类比存储器架构能比需要存取外部存储器的传统架构节省多少能量方面提供经验;此外该机构的另一个目标,是量化采用二进制方案在精确度、成本与处理量方面的折衷(tradeoff)。
加速器芯片通常能在一些热门的测试上提供约90%的精确度,例如ImageNet竞赛;Verkest表示,单位元资料型别目前有10%左右的精度削减,「但如果你调整你的神经网络,可以达到最高85%~87%的精确度。」他原本负责督导Imec的逻辑制程微缩技术蓝图,在Apple挖脚该机构的第一个AI项目经理之后,又兼管AI项目。
Verkest表示,理论上类比存储器单元应该能以一系列数值来储存权重(weights),但是「那些存储器元件的变异性有很多需要考量之处;」他指出,Imec的开发项目将尝试找出能提供最佳化精度、处理量与可靠度之间最佳化平衡的精度水平。
而Toon则认为聚焦于资料型别是被误导了:「低精度并没有某些人想得那么严重,存储器存取是我们必须修正之处;」他并未详细介绍Graphcore的解决方案,但声称该公司技术可提供比目前采用HBM2存储器的最佳GPU高40倍的存储器频宽。
在芯片架构方面,Imec的研究人员还未决定他们是要设计PIM或采用类比存储器结构;后者比较象是一种类比SoC,计算是在类比区块处理,可因此减少或免除数位-类比转换。不同种类的神经网络会有更适合的不同架构,例如卷积神经网络(CNN)会储存与重复使用权重,通常能以传统GPU妥善运作;归递神经网络(RNN)以及长短期记忆模型(long short-term memories,LSTMs)则倾向于在使用过后就抛弃权重,因此更适合表达式存储器结构

新的平行架构非常难编程,因此大多数供应商正在尝试建立在TensorFlow等现有架构中摄取程序码的途径。而Graphcore则是打造了一种名为Poplar的软件层,旨在以C++或Python语言来完成这项工作;Toon表示:「我们把在处理器中映射图形(graphs)的复杂性推到编译器(也就是扮演该角色的Poplar)。」
Graphcore的客户很快就会发现该程序会有多简单或是多困难;这家新创公司预计在年中将第一款产品出货给一线大客户,预期他们会在今年底采用该款芯片执行大型云端供应商的服务。Toon声称,其加速器芯片将能把CNN的速度提升五至十倍,同时间采用RNN或LSTM的更复杂模型则能看到100倍的效能提升。
学术界已经研究PIM架构数十年,而该架构越来越受到资料密集的机器算法欢迎,例如新创公司Mythic以及IBM Research都有相关开发成果。许多学术研究机构正在实验1~4位元的资料型别(data type),以减轻深度学习所需的沉重存储器需求;到目前为止,包括Arm等公司的AI加速器商用芯片设计都集中在8位元或更大容量的资料型别,部分原因是编程工具例如Google的TensorFlow缺乏对较小资料型别的支援。
Imec拥有在一家晶圆代工厂制作的40奈米制程加速器逻辑部份,而现在是要在自家晶圆厂添加一个MRAM层;该机构利用SRAM模拟此设计的性能,并且评估5奈米节点的设计规则。此研究是Imec与至少两家匿名IDM业者伙伴合作、仍在开发阶段的项目,从近两年前展开,很快制作了采用某种电阻式存储器(ReRAM)的65奈米PIM设计原型。
该65奈米芯片并非锁定深度学习算法,虽然Imec展示了利用它启动一段迷人的计算机合成音乐;其学习模式是利用了根据以音乐形式呈现、从传感器所串流之资料的时间序列分析(time-series analysis)。而40奈米低功耗神经网络加速器(Low-Energy Neural Network Accelerator,LENNA)则会锁定深度学习,在相对较小型的MRAM单元中运算与储存二进制权重。
Imec技术团队的杰出成员Diederik Verkest接受EE Times采访时表示:「我们的任务是定义出我们应该利用新兴存储器为机器学习开发什么样的半导体技术──或许我们会需要制程上的调整,」以取得最佳化结果。该机构半导体技术与系统部门执行副总裁An Steegen则表示:「AI会是制程技术蓝图演化的推手,因此Imec会在AI (以及PIM架构)方面下很多功夫──这方面的工作成果将会非常重要。」
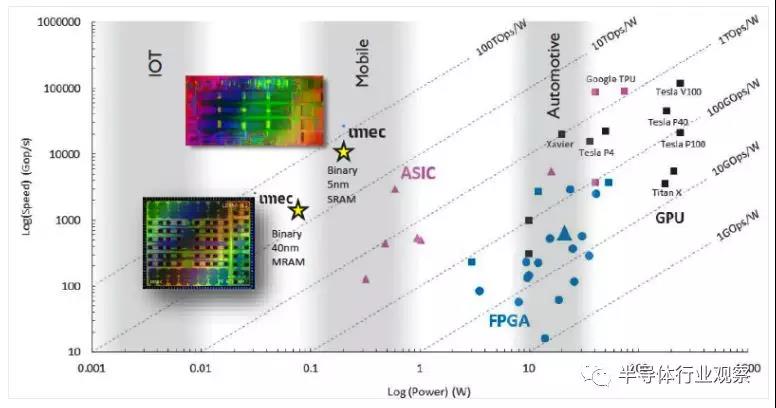
图:Imec声称其LENNA芯片在推论任务上的表现将超越现有的CPU与GPU(来源:Imec)
确实,如来自英国的新创公司Graphcore执行长Nigel Toon所言,AI标志着「运算技术的根本性转变」;该公司将于今年稍晚推出首款芯片。Toon在Imec年度技术论坛上发表专题演说时表示:「今日的硬件限制了我们,我们需要某种更灵活的方案…我们想看到能根据经验调整的(神经网络)模型;」他举例指出,两年前Google实习生总共花了25万美元电费,只为了在该公司采用传统x86处理器或Nvidia GPU的资料中心尝试最佳化神经网络模型。
实现复杂的折衷平衡
Imec希望LENNA能在关于PIM或类比存储器架构能比需要存取外部存储器的传统架构节省多少能量方面提供经验;此外该机构的另一个目标,是量化采用二进制方案在精确度、成本与处理量方面的折衷(tradeoff)。
加速器芯片通常能在一些热门的测试上提供约90%的精确度,例如ImageNet竞赛;Verkest表示,单位元资料型别目前有10%左右的精度削减,「但如果你调整你的神经网络,可以达到最高85%~87%的精确度。」他原本负责督导Imec的逻辑制程微缩技术蓝图,在Apple挖脚该机构的第一个AI项目经理之后,又兼管AI项目。
Verkest表示,理论上类比存储器单元应该能以一系列数值来储存权重(weights),但是「那些存储器元件的变异性有很多需要考量之处;」他指出,Imec的开发项目将尝试找出能提供最佳化精度、处理量与可靠度之间最佳化平衡的精度水平。
而Toon则认为聚焦于资料型别是被误导了:「低精度并没有某些人想得那么严重,存储器存取是我们必须修正之处;」他并未详细介绍Graphcore的解决方案,但声称该公司技术可提供比目前采用HBM2存储器的最佳GPU高40倍的存储器频宽。
在芯片架构方面,Imec的研究人员还未决定他们是要设计PIM或采用类比存储器结构;后者比较象是一种类比SoC,计算是在类比区块处理,可因此减少或免除数位-类比转换。不同种类的神经网络会有更适合的不同架构,例如卷积神经网络(CNN)会储存与重复使用权重,通常能以传统GPU妥善运作;归递神经网络(RNN)以及长短期记忆模型(long short-term memories,LSTMs)则倾向于在使用过后就抛弃权重,因此更适合表达式存储器结构
图:Imec可能会以存储器结构来打造LENNA,让运算留在类比功能区块(来源:Imec)
新的平行架构非常难编程,因此大多数供应商正在尝试建立在TensorFlow等现有架构中摄取程序码的途径。而Graphcore则是打造了一种名为Poplar的软件层,旨在以C++或Python语言来完成这项工作;Toon表示:「我们把在处理器中映射图形(graphs)的复杂性推到编译器(也就是扮演该角色的Poplar)。」
Graphcore的客户很快就会发现该程序会有多简单或是多困难;这家新创公司预计在年中将第一款产品出货给一线大客户,预期他们会在今年底采用该款芯片执行大型云端供应商的服务。Toon声称,其加速器芯片将能把CNN的速度提升五至十倍,同时间采用RNN或LSTM的更复杂模型则能看到100倍的效能提升。
免责声明:本文若是转载新闻稿,转载此文目的是在于传递更多的信息,版权归原作者所有。文章所用文字、图片、视频等素材如涉及作品版权问题,请联系本网编辑予以删除。
我要投稿
近期活动
- 安森美汽车&能源基础设施白皮书下载活动时间:2024年04月01日 - 2024年10月31日[立即参与]
- 2023年安森美(onsemi)在线答题活动时间:2023年09月01日 - 2023年09月30日[查看回顾]
- 2023年安森美(onsemi)在线答题活动时间:2023年08月01日 - 2023年08月31日[查看回顾]
- 【在线答题活动】PI 智能家居热门产品,带您领略科技智慧家庭时间:2023年06月15日 - 2023年07月15日[查看回顾]
- 2023年安森美(onsemi)在线答题活动时间:2023年06月01日 - 2023年06月30日[查看回顾]
分类排行榜
- 汽车电子电源行业可靠性要求,你了解多少?
- 内置可编程模拟功能的新型 Renesas Synergy™ 低功耗 S1JA 微控制器
- Vishay 推出高集成度且符合 IrDA® 标准的红外收发器模块
- ROHM 发布全新车载升降压电源芯片组
- 艾迈斯半导体推出行业超薄的接近/颜色传感器模块,助力实现无边框智能手机设计
- 艾迈斯半导体与 Qualcomm Technologies 集中工程优势开发适用于手机 3D 应用的主动式立体视觉解决方案
- 维谛技术(Vertiv)同时亮相南北两大高端峰会,精彩亮点不容错过
- 缤特力推出全新商务系列耳机 助力解决开放式办公的噪音难题
- CISSOID 和泰科天润(GPT)达成战略合作协议,携手推动碳化硅功率器件的广泛应用
- 瑞萨电子推出 R-Car E3 SoC,为汽车大显示屏仪表盘带来高端3D 图形处理性能
编辑推荐
小型化和稳定性如何兼得?ROHM 推出超小型高输出线性 LED 驱动器 IC,为插座型 LED 驱动 IC 装上一颗强有力的 “心脏”
众所周知,LED的驱动IC担负着在输入电压不稳定的情况下,为LED提供恒定的电流,并控制恒定(可调)亮度的作用。无论是室内照明,还是车载应用,都肩负着极为重要的使命。
- 关于反激电源效率的一个疑问
时间:2022-07-12 浏览量:9997
- 面对热拔插阐述的瞬间大电流怎么解决
时间:2022-07-11 浏览量:8766
- PFC电路对N线进行电压采样的目的是什么
时间:2022-07-08 浏览量:9401
- RCD中的C对反激稳定性有何影响
时间:2022-07-07 浏览量:7068
- 36W单反激 传导7~10M 热机5分钟后超标 不知道哪里出了问题
时间:2022-07-07 浏览量:5819
- PFC电感计算
时间:2022-07-06 浏览量:4051
- 多相同步BUCK
时间:2010-10-03 浏览量:37822
- 大家来讨论 系列之二:开机浪涌电流究竟多大?
时间:2016-01-12 浏览量:43112
- 目前世界超NB的65W适配器
时间:2016-09-28 浏览量:59984
- 精讲双管正激电源
时间:2016-11-25 浏览量:127845
- 利用ANSYS Maxwell深入探究软磁体之----电感变压器
时间:2016-09-20 浏览量:107485
- 【文原创】认真的写了一篇基于SG3525的推挽,附有详细..
时间:2015-08-27 浏览量:100144
